
How to learn Ceph | The reality that NOBODY is telling
“I launch commands but I don’t understand anything”. “I read documentation but when something fails I don’t even know where to start.” “I’ve been with Ceph for a year and I feel like I’m barely scratching the surface.” If any of these phrases resonate with you, you’re not alone. And most importantly: it’s not your fault.
After more than 10 years working with Ceph in production, teaching hundreds of administrators, and rescuing “impossible” clusters at 3AM, we have come to a conclusion that no one will tell you in official certifications: Ceph is brutally difficult to master. And not because you’re a bad administrator, but because the technology is inherently complex, constantly evolving, and the documentation assumes knowledge that no one explicitly taught you.
We’re not going to sell you a “learn Ceph in 30 days”. We want to tell you the truth about how you really learn, how long it takes, what misunderstandings will hold you back, and what is the most effective route to go from blindly throwing commands to having real expertise ;)
Why Ceph is so hard to learn (and it’s not your fault)
Complexity is not accidental: it is inherent
Ceph is not “just another storage system”. It is a massively distributed architecture that must solve simultaneously:
- Write consistency with multi-node replication and distributed consensus
- Continuous availability in the event of hardware failures (disks, nodes, complete racks)
- Automatic rebalancing of petabytes of data with no downtime
- Predictable performance under variable and multi-tenant loads
- Three completely different interfaces (block, object, filesystem) on the same basis
- Integration with multiple ecosystems (OpenStack, Kubernetes, traditional virtualization)
Each of these capabilities separately is a complex system. Ceph integrates them all. And here’s the problem: you can’t understand one without understanding the others. 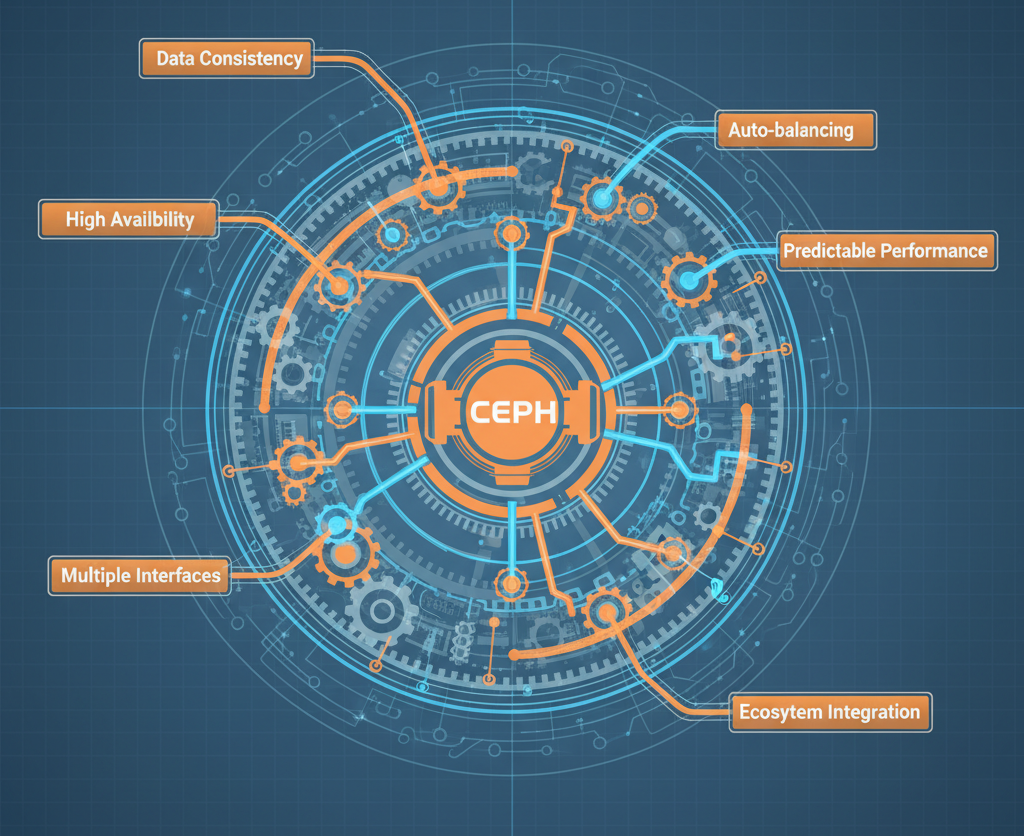
Beginner’s Mistake #1: Trying to learn Ceph as if it were just another stateless service. “I configure, issue commands, and it should work”. No. Ceph is a distributed system with shared state, consensus between nodes, and emergent behaviors that only appear under load or failure. If you don’t understand the underlying architecture, every problem will be an indecipherable mystery.
Documentation assumes knowledge that no one ever taught you
Read any page of the official Ceph documentation and you will find terms like:
- Placement groups (PGs)
- CRUSH algorithm
- BlueStore / FileStore
- Scrubbing and deep-scrubbing
- Peering and recovery
- OSDs up/down vs in/out
The documentation explains what they are, but not why they exist, what problem they solve, or how they interact with each other. It’s like trying to learn to program by starting with the language reference instead of the fundamental concepts.
Real example: A student wrote to us: “I have been 3 months trying to understand PGs. I read that ‘they are a logical abstraction’, but… why do they exist? why do they exist, why not map objects directly to OSDs?”
That question shows deep understanding. The answer (CRUSH map scalability, rebalancing granularity, metadata overhead) requires first understanding distributed systems, consistent hashing theory, and architecture trade-offs. No one teaches you that before releasing ceph osd pool create.
Constant evolution invalidates knowledge
Ceph changes FAST. And I’m not talking about optional features, but fundamental architectural changes:
- FileStore → BlueStore (2017): Completely changes how you write to disk.
- ceph-deploy → ceph-ansible → cephadm (2020): three different deployment tools in 5 years
- Luminous → Nautilus → Octopus → Pacific → Quincy → Reef → Squid: 7 major versions in 7 years, each with breaking changes.
- Crimson/Seastore (2026+): Complete rewrite of the OSD that will invalidate much of the tuning knowledge.
What you learned 2 years ago about FileStore tuning is completely irrelevant now. The PGs per pool that you were calculating manually are now managed by autoscaler. Networking best practices changed with msgr2.
Beginner (and expert) mistake #2: Learning configurations by rote without understanding why they exist. I saw an administrator manually configuring PG count with Luminous formulas…. on a Squid cluster with autoscaler enabled. The autoscaler ignored it, he didn’t understand why. Historical context matters to know what knowledge is obsolete.
How long it really takes to master Ceph
Let’s talk with real numbers based on our experience training managers:
Realistic learning progression
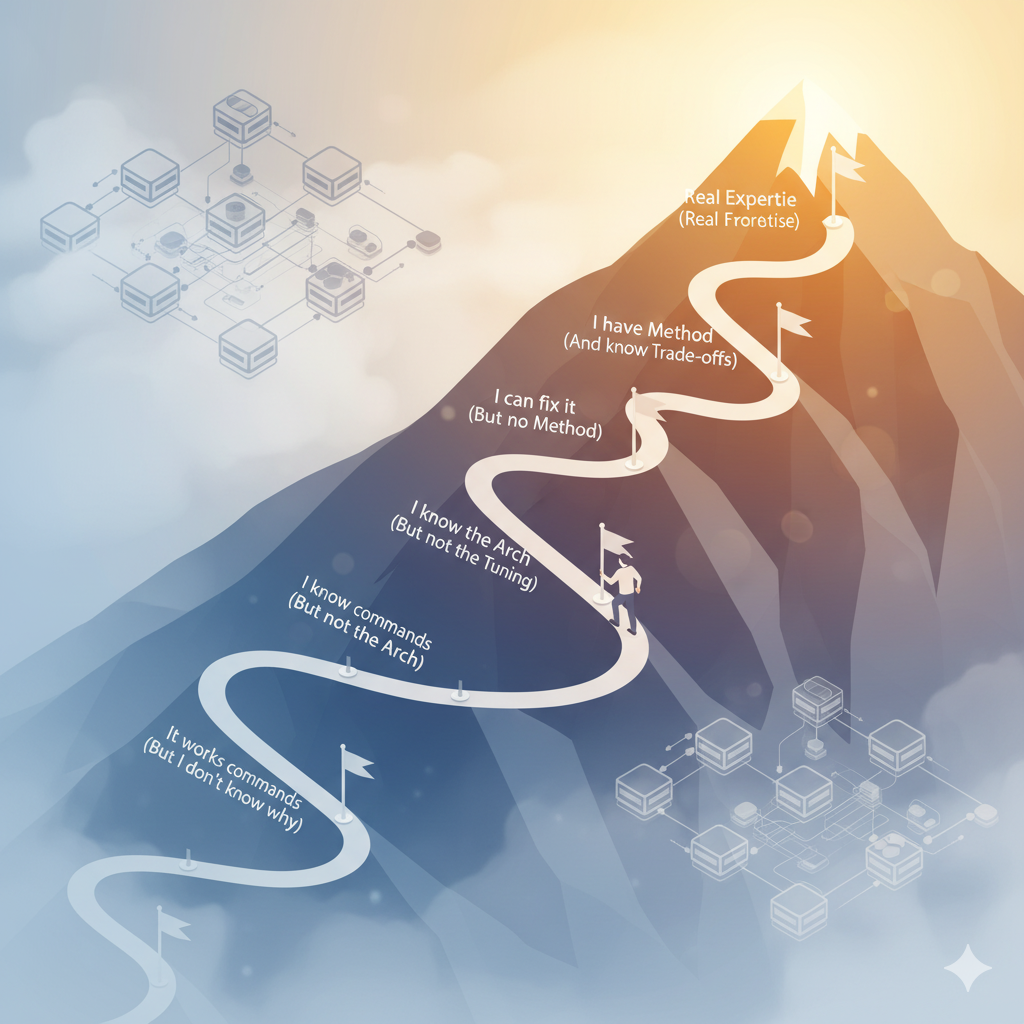
Month 1-2: “I don’t understand anything but it works”.
You follow tutorials. You launch commands ceph osd pool create, ceph osd tree. The cluster works… until it doesn’t. An OSD is marked as down and you panic because you don’t know how to diagnose.
Typical symptom: You copy commands from Stack Overflow without understanding what they do. “I fixed it” but you don’t know how or why.
Month 3-6: “I understand commands but not architecture”.
You have memorized the main commands. You know how to create pools, configure RBD, mount CephFS. But when PG 3.1f is stuck in peering comes up, you have no idea what “peering” means and how to fix it.
Typical symptom: You solve problems by trial-and-error by restarting services until it works. There is no method, there is luck.
Month 6-12: “I understand architecture but not tuning”.
You finally understand MON/OSD/MGR, the CRUSH algorithm, what PGs are. You can explain the architecture on a whiteboard. But your cluster performs poorly and you don’t know if it’s CPU, network, disks, or configuration.
Typical symptom: You read about BlueStore tuning, change parameters randomly, don’t measure before/after. Performance remains the same (or worse).
Year 1-2: “I can troubleshoot but no method”.
You have already rescued some clusters. You know how to use
Typical symptom: You can fix problems… eventually. But you can’t predict them or explain to your boss how long the solution will take.
Year 2-3: “I have method and understand trade-offs”.
You diagnose systematically: collect symptoms, formulate hypotheses, validate with specific tools. You understand trade-offs: when to use replication vs. erasure coding, how to size hardware, when NVMe is worthwhile.
Typical symptom: Your response to problems is “let me check X, Y and Z” with a clear plan. You can estimate realistic recovery times.
Year 3+: real expertise
You design architectures from scratch considering workload, budget, SLAs. Make disaster recovery without manual. Optimize BlueStore for specific loads. You understand the source code enough to debug rare behaviors.
Typical symptom: Other admins call you when a cluster is “impossible”. You take 20 minutes to identify the problem that they have been attacking for 3 days.
The good news: You can SIGNIFICANTLY accelerate this progression with structured training. A good 3-day course can condense 6 months of trial-and-error. Not because it “teaches faster”, but because it saves you from dead ends and misunderstandings that consume weeks.
Typical misunderstandings that hold back your learning
Misunderstanding #1: “More hardware = more performance”.
I have seen clusters with 40 OSDs performing worse than clusters with 12. Why? Because they had:
- Public network and cluster on the same interface (guaranteed saturation)
- CPU frequency governor in “powersave” (5x degradation in replication)
- PG count totally unbalanced between pools
- BlueStore very low cache for RGW loads
The reality: Ceph performance depends on the weakest link. A single-threaded bottleneck in a MON can bring down the whole cluster. More misconfigured hardware only multiplies the chaos.
Misunderstanding #2: “Erasure coding always saves space”.
A student once proudly said: “I moved my entire cluster to erasure coding 8+3 to save space”. We asked him, “What workload do you have?” – “RBD with frequent snapshots.” Whoops.
Erasure coding with workloads that do small overwrites (RBD, CephFS) is TERRIBLE for performance. And the space “savings” is eaten up with partial stripes and metadata overhead.
The reality: EC is great for object storage cold data (RGW archives). It is terrible for block devices with high IOPS. Knowing the workload before deciding architecture is fundamental.
Misunderstanding #3: “If ceph health says HEALTH_OK, all is well.”
No. HEALTH_OK means that Ceph did not detect problems known to him. It does not detect:
- Progressive disk degradation (SMART warnings)
- Intermittent network packet loss
- Memory leaks in daemons
- Scrubbing that has not been completed for 2 weeks
- PGs with suboptimal placement causing hotspots
The reality: You need external monitoring (Prometheus + Grafana minimum) and review metrics that Ceph does not expose on ceph health. HEALTH_OK is necessary but not sufficient.
Misunderstanding #4: “I read the official doc and that’s enough”.
The official documentation is reference material, not teaching material. Assume you already understand:
- Distributed systems (Paxos, quorum, consensus)
- Storage fundamentals (IOPS vs throughput, latency percentiles)
- Networking (MTU, jumbo frames, TCP tuning)
- Linux internals (cgroups, systemd, kernel parameters)
If you don’t bring that foundation, the doc will confuse you more than help.
The reality: You need additional resources: academic papers on distributed systems, blogs of real experiences, training that connects the dots that the doc omits.
Typical mistakes (that we all make)
Beginner’s mistakes
Do not configure cluster network: The public network is saturated with internal replication. Performance plummets. Solution: --cluster-network from day 1.
Use defaults for PG count: In pre-Pacific versions you would create pools with 8 PGs… for a pool that would grow to 50TB. Impossible to rebalance later. Solution: Autoscaler or calculate well from the beginning.
Not understanding the difference OSD up/down vs in/out: You take out an OSD for maintenance with ceph osd out and immediately start massive rebalancing that takes 8 hours. You wanted noout. Oops.
Intermediate errors
Oversized erasure coding: Configure 17+3 EC in cluster of 25 nodes. One node crashes and the cluster goes into read-only mode because there are not enough OSDs to write to. Trade-off not understood.
Ignore the I/O scheduler: Use deadline scheduler with NVMe (absurd). Or none scheduler with HDD (disastrous). The right scheduler matters 20-30% of performance.
Don’t plan disaster recovery: “We have 3x replication, we are safe”. Then a whole rack goes down and they lose quorum of MONs. They never practiced recovery. Panic.
Expert mistakes (yes, we make them too)
Over-tuning: Change 15 BlueStore parameters simultaneously “to optimize”. Something breaks. Which of the 15 changes was it? Nobody knows. Principle: change ONE thing, measure, iterate.
Relying too much on old knowledge: Applying tuning techniques from FileStore to BlueStore. Doesn’t work because the internal architecture is totally different. Historical context matters.
Not documenting architectural decisions: 2 years ago you decided to use EC 8+2 in a certain pool for X reason. Nobody documented it. Now a new admin wants to “simplify” to replication. Disaster avoidable with documentation.
The most effective way to learn Ceph
Phase 1: architectural fundamentals (40-60 hours)
Before touching a command, understand:
- What problem does Ceph solve (vs NAS, vs SAN, vs cloud storage)?
- RADOS architecture: how MON, OSD, MGR work
- CRUSH algorithm: why does it exist, what problem does it solve?
- Placement groups: the abstraction that makes the system scalable
- Difference between pools, PGs, objects, and their mapping to OSDs
How to study this: Not with commands, but with diagrams and concepts. A good fundamentals course is 100x more effective than “deploy in 10 minutes” tutorials.
Recommended course: Ceph administration
Level: fundamental
3 days intensive
Program specifically designed to build a solid foundation from scratch. Assumes no prior knowledge of distributed storage.
Phase 2: advanced configuration and troubleshooting (60-80 hours)
With solid foundations, you now go deeper:
- BlueStore internals: how the data is actually written
- CRUSH rules customized for complex topologies
- Performance tuning: identifying bottlenecks
- Multi-site RGW for geo-replication
- RBD mirroring for disaster recovery
- Systematic troubleshooting with method
The goal: To move from “I can configure” to “I understand why I configure this way and what trade-offs I am making”.
Recommended course: Advanced Ceph
Level: advanced
3 days intensive
For administrators who already have cluster running but want to master complex configurations and prepare for EX260.
Phase 3: critical production operations (80-100 hours)
The final leap: from “I know how to configure and troubleshoot” to “I can rescue clusters in production at 3AM”.
- Forensic troubleshooting: diagnosing complex multi-factor failures
- Disaster recovery REAL: recovery of corrupted metadata, lost journals
- Performance engineering: kernel and hardware optimization
- Architectures for specific loads: AI/ML, video streaming, compliance
- Security hardening and compliance (GDPR, HIPAA)
- Scaling to petabytes: problems that only appear on a large scale
The objective: Real verifiable expertise. Eliminate that “respect” (fear) of critical scenarios.
Recommended course: Ceph production engineering
Level: expert
3 days intensive
The only course on the market focused 100% on critical production operations. No simulations – real problems.
Continuous practice: the non-negotiable ingredient
Here is the inconvenient truth: you can do the 3 courses and still have no expertise if you don’t practice. Theoretical knowledge is forgotten if you don’t apply it.
SIXE’s recommendation after each course:
- Set up a practice cluster (can be local VMs or cheap cloud).
- Intentionally breaks things: kills OSDs, fills disks, saturates network
- Practice recovery without manual: can you recover without Google?
- Measures everything: benchmarks before/after each change
- Document your learning: blog, notes, whatever.
Pro tip: The best Ceph administrators I know maintain a permanent “lab cluster” where they test crazy things. Some even have scripts that inject random bugs to practice troubleshooting. Sounds extreme, but it works.
Conclusion: the road is long but can be accelerated.
If you made it this far, you are already in the top 10% of Ceph administrators out of pure intent to learn correctly. Most drop out when they realize the real complexity.
The uncomfortable truths you must accept:
- Mastering Ceph takes 2-3 years of continuous hands-on experience. There are no magic shortcuts.
- You’re going to make mistakes. Lots of them. Some in production. It’s part of the process.
- Knowledge depreciates quickly. What you learn today will be partially obsolete in 18 months.
- Official documentation will never be tutorial-friendly. You need complementary resources.
But there is also good news:
- Demand for Ceph experts massively exceeds supply. Good time to specialize.
- You can accelerate the 6-12 month learning curve with structured training that avoids dead ends.
- Once you “click” on the fundamental architecture, the rest is logically built on that foundation.
- The community is generally open to help. You are not alone.
Our final advice after 10+ years with Ceph: Start with solid fundamentals, practice constantly, and don’t be afraid to break things in test environments. The best administrators I know are the ones who have broken the most clusters (in labs) and meticulously documented every recovery.
And if you want to significantly accelerate your learning curve, consider structured training that condenses years of practical experience into intensive weeks. Not because it’s easier, but because it saves you the 6 months we all waste attacking problems that someone else has already solved.
Where to start today?
- If you are a total beginner: Ceph administration course
- If you already manage a cluster: Advanced Ceph Course
- If you are 2+ years old and you want real expertise: Ceph production engineering
Or just set up a cluster of 3 VMs, break things, and learn troubleshooting. The path is yours, but it doesn’t have to be lonely.


